728x90
1. 데이터 파악하기
| 함수 | 기능 |
| head() | 앞부분 출력 |
| tail() | 뒷부분 출력 |
| shape | 행, 열 개수 출력 |
| info() | 변수 속성 출력 |
| describe() | 요약 통계량 출력 |
exam 데이터를 파악해보자.
import pandas as pd
exam = pd.read_csv("C:/Users/anjiyoung/Documents/exam.csv")
head() 데이터 앞부분 확인하기

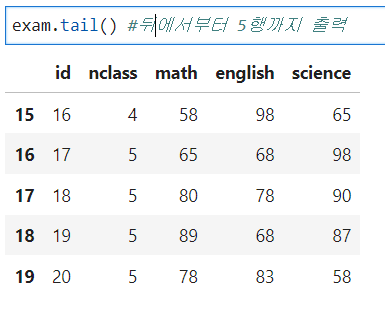
tail() - 데이터 뒷부분 확인하기
shape - 데이터가 몇 행, 몇 열로 구성되는지 알아보기

info - 변수 속성 파악하기

Non-Null Count: 결측치를 제외하고 구한 값의 개수
변수속성: int64(정수), float64(실수), object(문자), datetime64(날짜시간)
64: 64비트
- 1비트로 두 개의 값 표현 가능
- int64: 2^64개의 정수 표현 가능
describe() - 요약 통계량 구하기

| 출력값 | 통계량 | 설명 |
| count | 빈도(frequency) | 값의 개수 |
| unique | 고유값 빈도 | 중복을 제거한 범주의 개수 |
| top | 최빈값 | 개수가 가장 많은 값 |
| freq | 최빈값의 빈도 | 개수가 가장 많은 값의 개수 |
| mean | 평균(mean) | 모든 값을 더해 값의 개수로 나눈 값 |
| std | 표준편차(standard deviation) | 변수의 값들이 평균에서 떨어진 정도를 나타낸 값 |
| min | 최소값(minimum) | 가장 작은 값 |
| 25% | 1사분위수 | 하위25%(4분의 1) |
| 50% | 중앙값(median) | 하위 50%(중앙 |
| 75% | 3사분위수 | 하위 75% 지점에 위치한 값 |
| max | 최댓값 | 가장 큰 값 |
2. 변수명 바꾸기
mpg = mpg.rename(columns = {'manufacturer':'company'})
3. 파생변수 만들기
mpg['total'] = (mpg['cty']+mpg['hwy'])/2 # 변수 조합
mpg['test'] = np.where(mpg['total'] >= 20, 'pass', 'fail') # 조건문 활용
'성동1기 전Z전능 데이터 분석가 과정' 카테고리의 다른 글
| [성동1기 전Z전능 데이터 분석가] 43일차 프로젝트 (0) | 2023.12.13 |
|---|---|
| [성동1기 전Z전능 데이터 분석가] 37일차 python 프로젝트(통계분석) (0) | 2023.12.05 |
| [성동1기 전Z전능 데이터 분석가] 32일차 python 데이터 프레임 (0) | 2023.11.28 |
| [성동1기 전Z전능 데이터 분석가] 32일차 python 기초 - 함수, 패키지 (0) | 2023.11.28 |
| [성동1기 전Z전능 데이터 분석가] 31일차 python 기초 - 제어문 (0) | 2023.11.27 |


